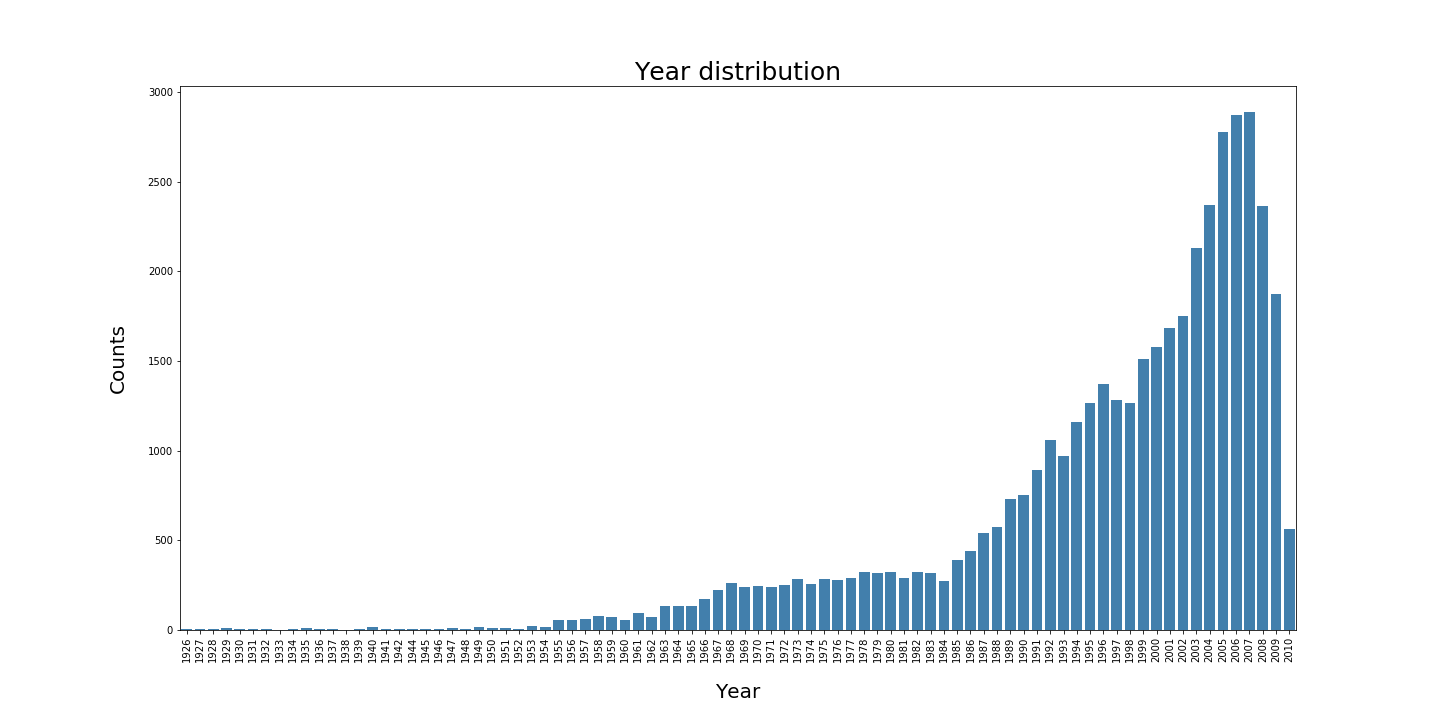
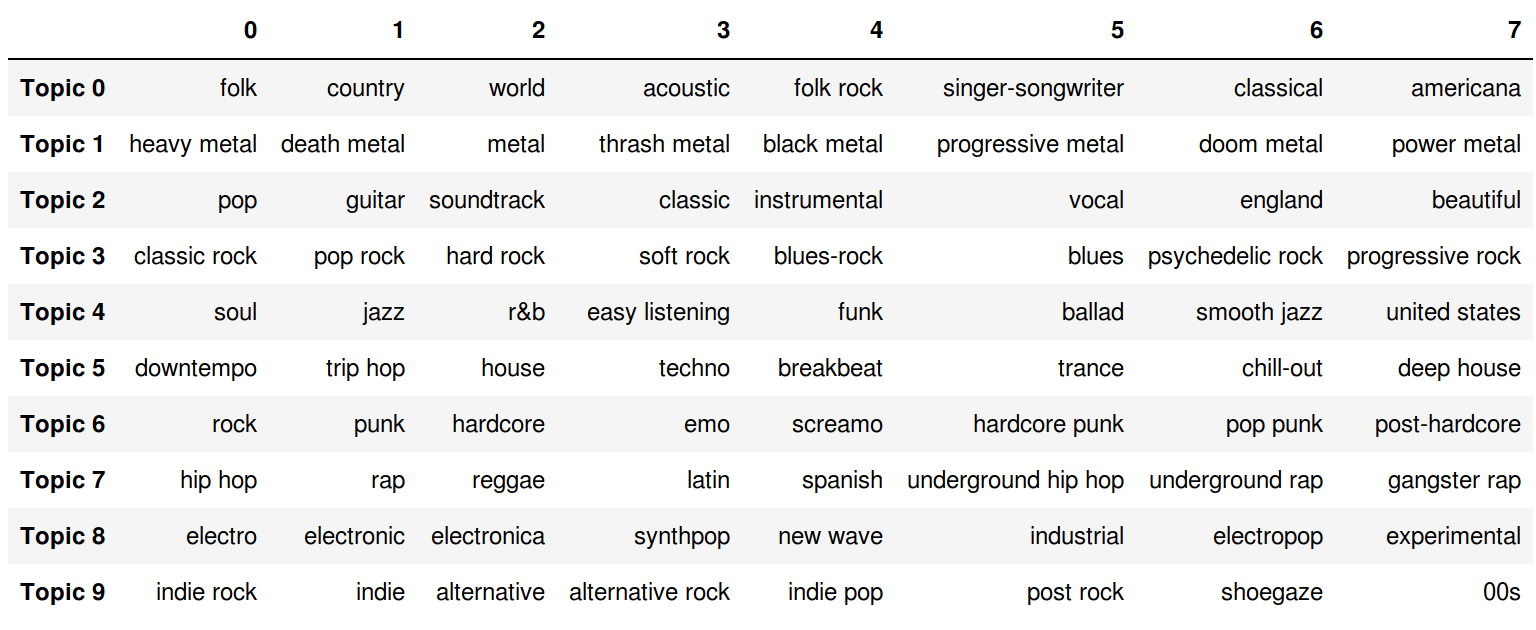
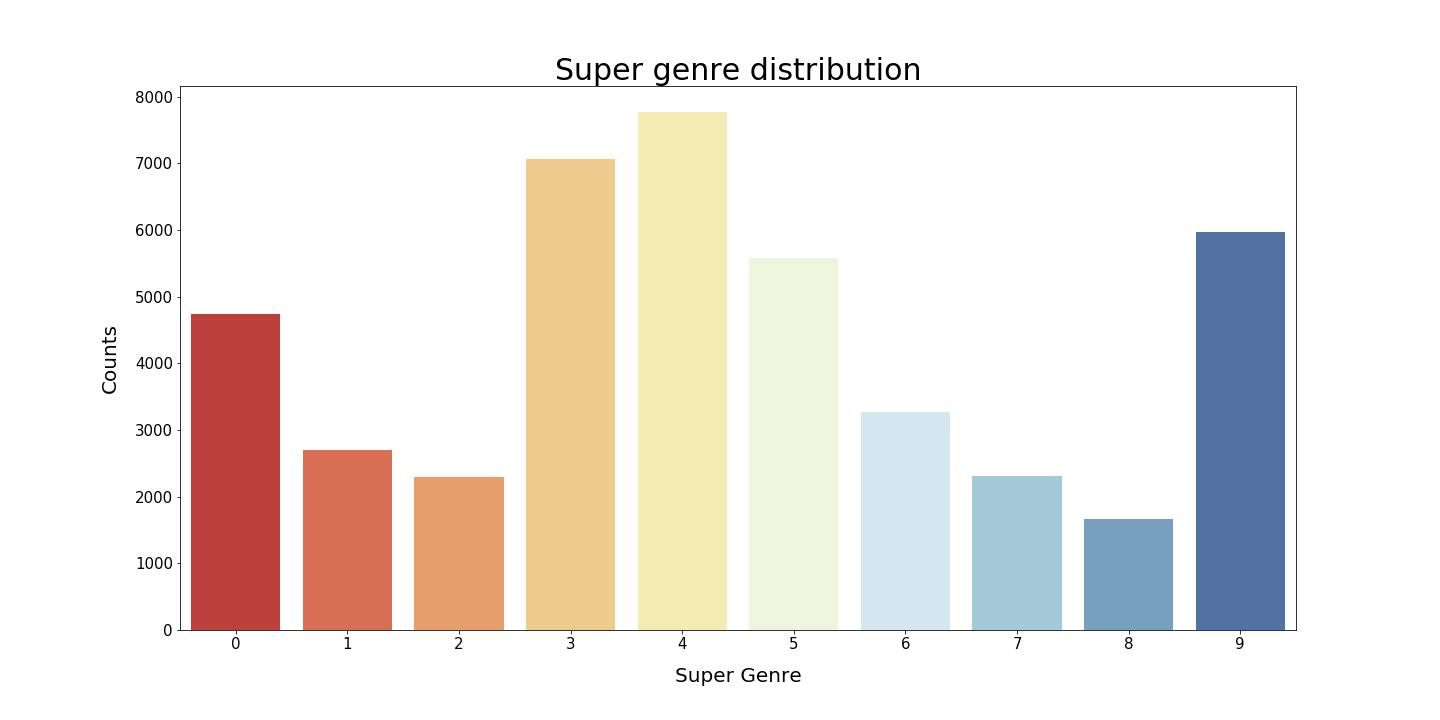
Genre analysis through space:
Now, lets try to put our genre classification into another perspective. More precisely, we want to confront the given labeling (tags) of the songs with some of their content informations. To do that, we focused on these given features : "tempo","loudness" with respect to the our genre labeling.
However, we can see below, that the box plots for the features : “loudness” and "tempo" are not really relevant with respect to the defined genres.
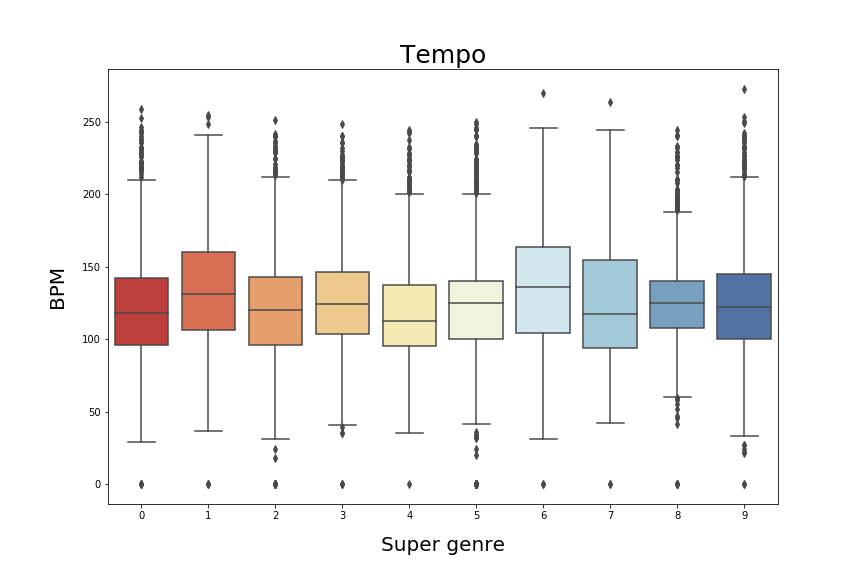
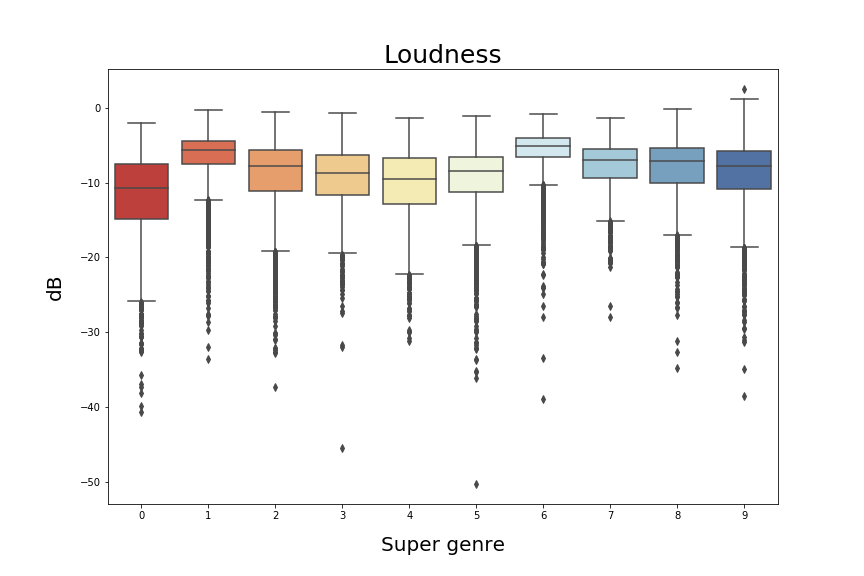
The correlations between them do not give better results neither:
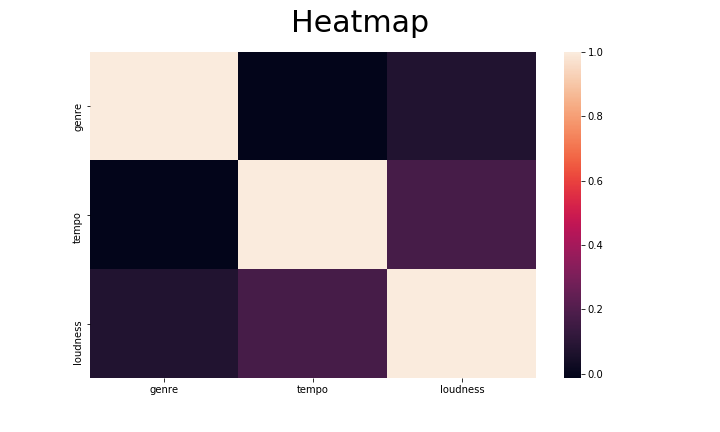
We thus decided to have a closer look at the “segment_timbre” feature.
According to the Echonest documentation:
- Segments: are a set of sound entities (typically under a second) each relatively uniform in timbre and harmony. Segments are characterized by their perceptual onsets and duration in seconds, loudness (dB), pitch and timbral content.
- The segment_timbre is a 12-dimensional vector which captures the “tone colour" for each segment of a song. In order to facilitate our calculations we decided to take the mean of all segments to represent each song with one single vector of size 12.
In order to see if we could get information from it, we started by applying on the vectors of a given genre, a principal component analysis (PCA). PCA, is a statistical procedure that uses an orthogonal transformation to convert a set of observations of possibly correlated variables into a set of values of linearly uncorrelated variables called principal components. We can see below, that the representation in space of two sets of songs, (coming from two different genre with respect to their two principal components values give some relevant results. Indeed, we can see well defined separation between the two music genre.
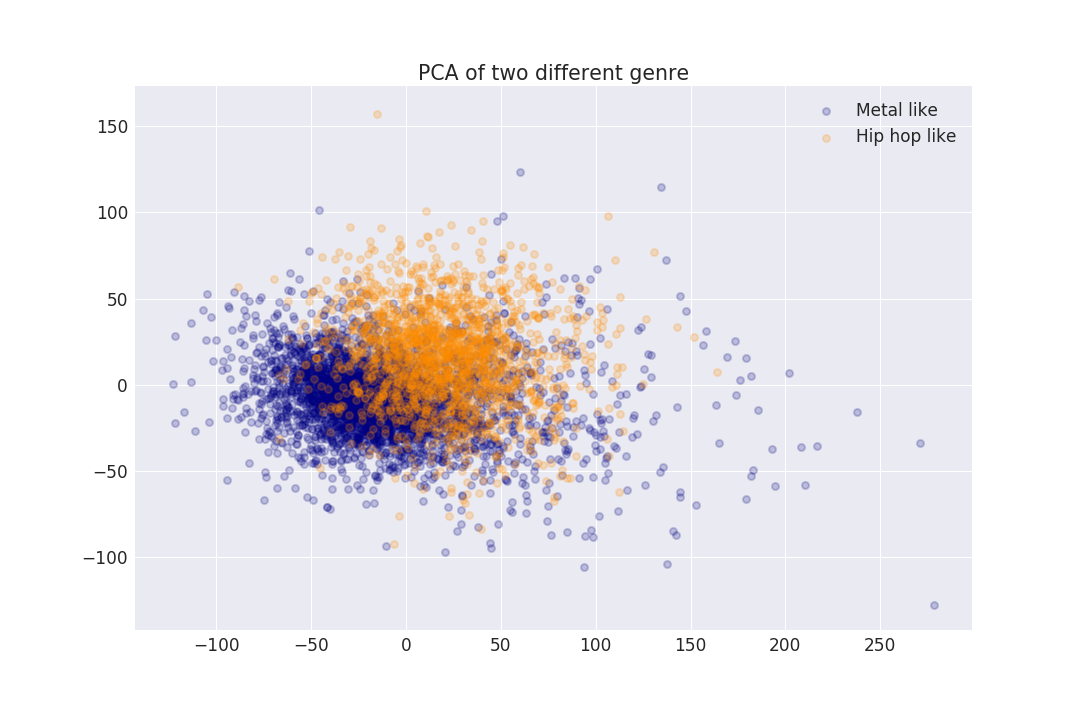
However, we can see that the points overlap. We thus decided to try a 3d approach.